

A webpage is a collection of data, and the data can be anything text, image, video, file, links, and so on. With the help of web scraping, we can extract that data from the webpage. Here, we will discuss how to extract all website links in Python.
Let's say there is a webpage, and you want to extract only URLs or links from that page to know the number of internal and external links. There are many web applications on the internet that charge hundreds of dollars to provide such features, where they extract valuable data from other webpages to get insights into their strategies.
You do not need to buy or rely on other applications to perform such trivial tasks when you can write a Python script that can extract all the URL links from the webpage, and that's what we are going to do in this tutorial.
How to Extract All Website Links in Python?
Here, in this Python tutorial, we will walk you through the Python program that can extract links or URLs from a webpage. However, before we dive into the code, let's install the required libraries that we will be using in this Python tutorial.
Install Required Libraries
Here is the list of all required libraries and how to install them that we will be going to use in this tutorial:
1) Python
requests
Library
requests
is the de-facto Python library to make HTTP requests. We will be using this library to send GET requests to the URL of the webpage. You can install the requests library for your Python environment using the following pip install command:
pip install requests
2) Python
beautifulsoup4
Library
beautifulsoup4
is an open-source library that is used to extract or pull data from an HTML or XML page. In this tutorial, we will be using this library to extract
<a>
tag
href
links from the HTML of the webpage. To install beautifulsoup for your Python environment, run the following pip install command:
pip install beautifulsoup4
3) Python Colorama Library
The
colorama
library is used to print colorful text output on the terminal or command prompt. This library is optional for this tutorial, and we will be using this library only to print the output in a colorful format. To install
colorama
for your Python environment, run the following pip install command:
pip install colorama
Alright then, we are all set now. Open your best Python IDE or text editor and start coding.
How to Extract URLs from Webpages in Python?
Let's begin with importing the required modules.
#modules
from colorama import Back
import requests
from bs4 import BeautifulSoup
#for windows
from colorama import init
init()
We are using a Windows system, and that's why we need to mention two additional statements,from colorama import initandinit(). This is because, on Windows, we need to filter the ANSI escape sequence out of any text sent to stdout orstderrand replace them with equivalent Win32 calls.
If you are on Mac or Linux, then you do not need to write the above two statements. Even if you write them, the two statements will have no effect. After initializing the colorama
init()
method, let's define the webpage URL with the
url
identifier and send a GET request to the URL.
#page url
url = r"https://www.techgeekbuzz.com/"
#send get request
response = requests.get(url)
Now, we can parse the response HTML text using the beautifulSoup() module and find all the <a> tags present in the response HTML page.
#parse html page
html_page = BeautifulSoup(response.text, "html.parser")
#get all <a> tags
all_urls = html_page.findAll("a")
The
findAll()
function will return a list of all <a> tags present in the
html_page
. As we want to extract internal and external URLs present on the web page, let's define two empty
Python sets
, namely
internal_urls
and
external_urls
.
internal_urls = set()
external_urls =set()
Next, we will loop through every <a> tag present in the
all_urls
list and get their
href
attribute value using the
get()
function because
href
attribute has the link URL value.
for link in all_urls:
href=link.get('href')
if href:
if r"techgeekbuzz.com" in href: #internal link
internal_urls.add(href)
elif href[0]=="#": #same page target link
internal_urls.add(f"{url}{href}")
else: #external link
external_urls.add(href)
add()
is the set method that adds elements to the set object. Now, let's print all internal URLs with a green background and external links with a red background.
print( Back.MAGENTA + f"Total External URLs: {len(internal_urls)}\n")
for url in internal_urls:
print(Back.GREEN + f"Internal URL {url}")
print(Back.MAGENTA + f"\n\nTotal External URLs: {len(external_urls)}\n")
for url in external_urls:
print(Back.RED + f"External URL {url}")
Put all the code together and execute.
Python Program to Extract URLs from the Webpage
#modules
from colorama import Back
import requests
from bs4 import BeautifulSoup
#set windows
from colorama import init
init()
#page url
url = r"https://www.techgeekbuzz.com/"
#send get request
response = requests.get(url)
#parse html page
html_page = BeautifulSoup(response.text, "html.parser")
#get all tags
all_urls = html_page.findAll("a")
internal_urls = set()
external_urls =set()
for link in all_urls:
href=link.get('href')
if href:
if r"techgeekbuzz.com" in href: #internal link
internal_urls.add(href)
elif href[0]=="#": #same page target link
internal_urls.add(f"{url}{href}")
else: #external link
external_urls.add(href)
print( Back.MAGENTA + f"Total External URLs: {len(internal_urls)}\n")
for url in internal_urls:
print(Back.GREEN + f"Internal URL {url}")
print(Back.MAGENTA + f"\n\nTotal External URLs: {len(external_urls)}\n")
for url in external_urls:
print(Back.RED + f"External URL {url}")
Output
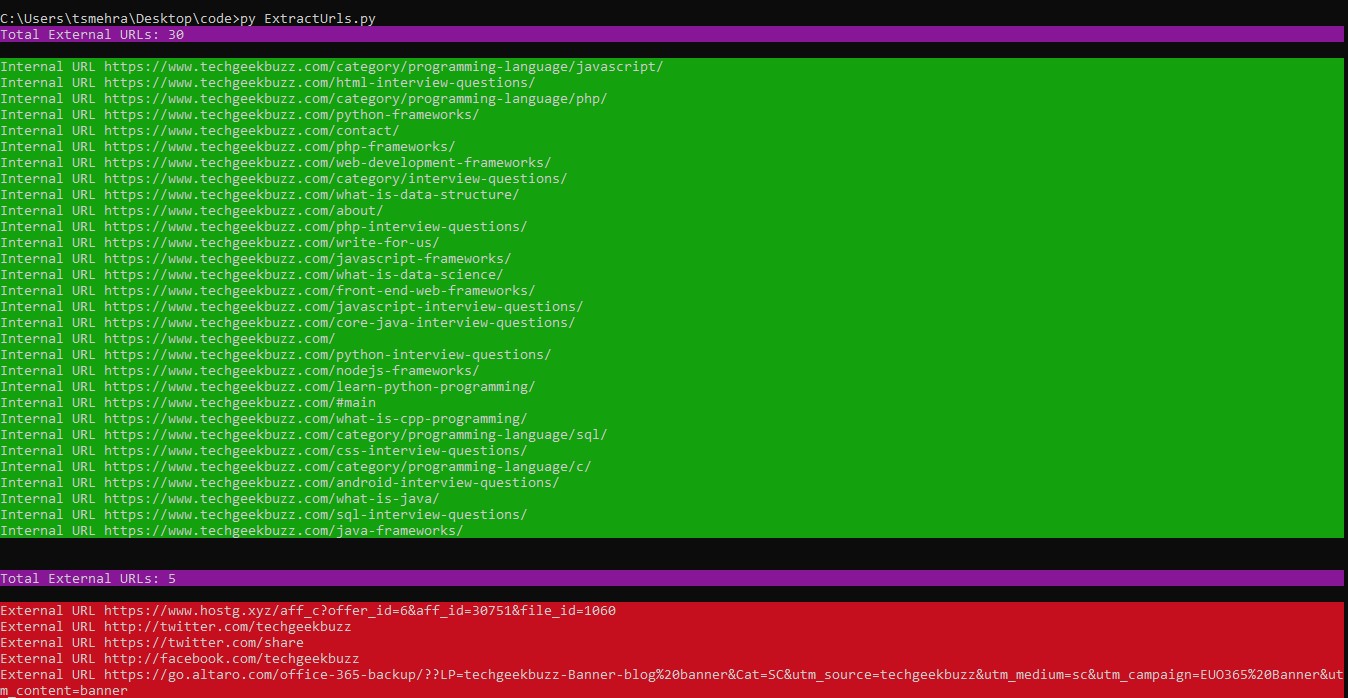
Conclusion
In this tutorial, you learned how to extract all website links in Python? The above program is an application of web scraping with Python. We would recommend you read the official documentation of beautifulsoup4 and requests to know more about web data extraction with Python.
People are also reading:
- Geolocation in Python
- Python map() function
- Starting Python Coding on a MacBook
- Install Python package using Jupyter Notebook
- Python Delete Emails
- Histogram Plotting in Python
- Python Check If File or Directory Exists
- Absolute vs Relative Imports in Python
- Python Timeit()
- Data Visualization in Python



Leave a Comment on this Post