

A web page can show text, images, files, and video data on the browser. For the multi-media data like files, images, and videos we generally have the source address as the attribute to the corresponding HTML tags.
Let's say there is a web page on the internet and you want to download all its images locally using Python. So how would you do that?
In this tutorial, I will walk you through the Python program that can download all the images from a web page and save them locally. Before we write the Python program let's install the libraries that we have used in this tutorial.
Required Libraries
Python
requests
library
In this tutorial, we have used the
requests
library to send HTTP GET requests to the web page and its image URLs, to get the web page as well as image data respectively. You can install the requests library for your Python environment using the following pip install command.
pip install requests
Python
beautifulsoup4
library
The
beautifulsoup4
library is used to parse and extract data from HTML and XML files. In this tutorial, we will be using this to get all the image tags and their source
src
attribute value. To install the beautifulsoup library you can run the following pip command on your terminal or command prompt.
pip install beautifulsoup4
In this tutorial, I will be downloading all the images from our homepage "techgeekbuzz.com". Now let's get started with the Python program.
How to Download All Images from a Web Page in Python?
Let's begin with importing the required module in our script
import requests
from bs4 import BeautifulSoup
Now let's define the url and send the get request to it.
url ="https://www.techgeekbuzz.com/"
#send get request
response = requests.get(url)
#parse response text
html_page = BeautifulSoup(response.text, 'html.parser')
The
get()
function will send the HTTP get request to the specified url (techgeekbuzz.com in our case).
BeautifulSoup(response.text, 'html.parser')
function will parse the
response.text
data which is actually a string representation of techgeekbuzz.com HTML code. Now let's find out all the <img> tags from the html_page/.
images = html_page.find_all("img")
The
find_all("img")
will return a list of all <img> tags present in the
html_page
. Now let's loop over every image tag, get its
src
attribute value, send HTTP GET request to the
src
value to get the image data in bytes, and at last, write the image byte data using
Python file handling
.
for index, image in enumerate(images):
image_url= image.get("src") #img src value
image_extension= image_url.split(".")[-1] #get image extension
#get image data
image_bytes = requests.get(image_url).content
if image_bytes:
#write the image data
with open(f"Image {index+1}.{image_extension}", "wb") as file:
file.write(image_bytes)
print(f"Downloading image {index+1}.{image_extension}")
get("src")
function will get the value of
img
src attribute.
split(".")[-1]
function will get the Image extension.
get(image_url).content
function will send an HTTP GET request to the image_url and return the image data in bytes.
open(f"Image {index+1}.{image_extension}", "wb")
statement will open a new file in write binary mode.
write(image_bytes)
function will write the binary data of the image and save it locally. Now you can put all the above code together and execute it.
Python program to download Images from a web-page
import requests
from bs4 import BeautifulSoup
url ="https://www.techgeekbuzz.com/"
#send get request
response = requests.get(url)
html_page = BeautifulSoup(response.text, 'html.parser')
images = html_page.find_all("img")
for index, image in enumerate(images):
image_url= image.get("src") #img src value
image_extension= image_url.split(".")[-1] #get image extension
#get image data
image_bytes = requests.get(image_url).content
if image_bytes:
#write the image data
with open(f"Image {index+1}.{image_extension}", "wb") as file:
file.write(image_bytes)
print(f"Downloading image {index+1}.{image_extension}")
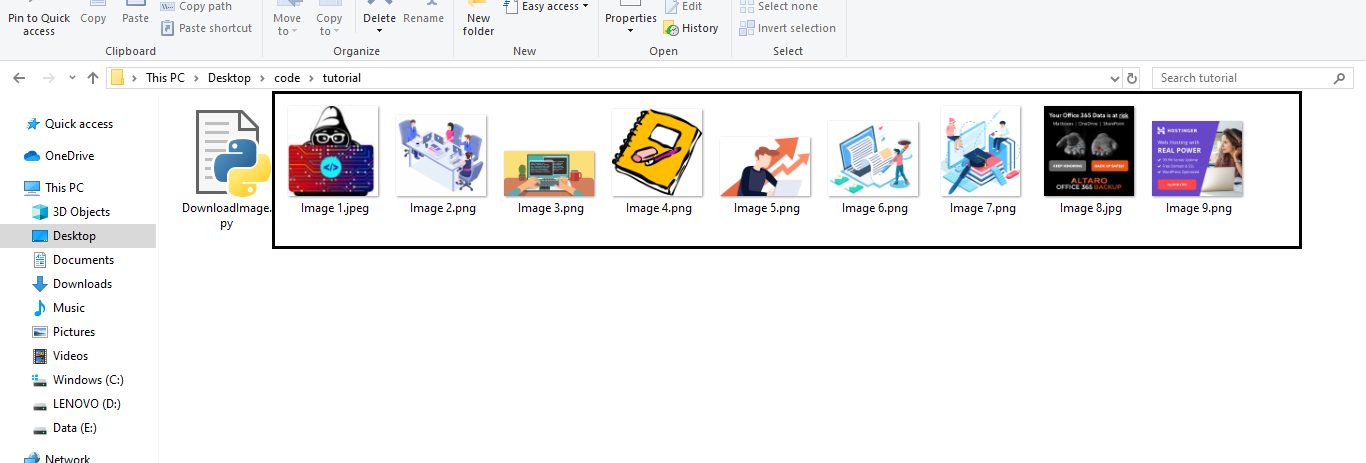
Output
Downloading image 1.jpeg
Downloading image 2.png
Downloading image 3.png
Downloading image 4.png
Downloading image 5.png
Downloading image 6.png
Downloading image 7.png
Downloading image 8.jpg
Downloading image 9.png
When you execute the above program you will see a similar output on the terminal or output console. You can also check your directory where your Python script is located, and whether all the images downloaded on your system or not.
Conclusion
In this Python tutorial, we learned how can we download images from a web page using Python?.
In the above program, I have used the GET request two times one to get the HTML web page of the url and the second to get the image byte data from the image url. To download or save the image locally I have used the Python file handling where I have opened the file in write binary mode and wrote the image binary data in the file.
If you want to know more about how to access data from the internet using Python , then I have also written an article on how to extract all web links from a web page using Python, you can click here to read that tutorial too.
People are also reading:
- Python Keyboard Module
- Check File Size Using Python
- Python Single and Double Underscore
- Current Date and Time in Python
- Python strptime()
- Extract images from PDF in Python
- Operator Overloading in Python
- Python Multiple Inheritance
- Directory and File Management in Python
- Python Number, Type Conversion and Mathematics
- Lambda Function in Python


