

Internet is the hub of data, and with the help of web-scraping tools, we can grab the specific data from the websites. Let’s say you want to pull the data of top 20 trending videos on YouTube, although big websites like YouTube, Facebook, Twitter provide dedicated REST APIs for such interaction or transfer of data, you can also use web-scraping to pull such open data. In this article on accessing internet data with Python, you will learn about what is web scraping in Python and how to extract or pull data from a website using Python web-scraping.
What is Web-Scraping?
Web Scraping is a technique of extracting or accessing data from websites. With the help of web-scraping, you can pull the static data provided by a website or web-page. In web-scraping, we parse a web-page which can be in any format HTML, XML, JSON, etc, and extract its data. Generally in web-scrapping, we extract data from HTML pages, because most of the website uses HTML to render their pages. XML and JSON format pages are often used with REST APIs which is a completely different topic. There always a debate on Is Web Scraping Legal or not? For most of the cases, it is legal where you are using the scrap data for study and research purposes. There are also many websites that prohibit web-scrapping, and when you sent a request to their pages you get either 40X or 50X responses.
Get Started with Python Web-Scraping
When it’s come to web scraping with Python or accessing data from the internet with Python, we only required two Python modules requests and beautifulsoup4.
How to access data from the internet with Python?
In order to access the data, first, we need to send a request to the page which data we want to access or scrape. And this can be done with the help of the Python requests library. After sending the request to the page or server, in response we receive the page HTML or XML format. Once we get the response we can parse that HTML page with the help of Python beautiful soup and pull the specific data we required.
Python libraries for web-scraping
The basic we only required requests and beautifulsoup4 libraries to perform web-scarping in Python. However, there are many other powerful Python libraries that can also be used for web scraping with Python such as scrapy, selenium, etc. But for this tutorial requests and beautifulsoup4 will do the trick.
Python requests Library
requests
is the Python defacto library for making HTTP requests. Using this library we can send HTTP requests to a specific URL, and in response, we get the web-page HTML details if the request is successful. To install the requests library for your Python environment run the following pip command on your Python terminal.
pip install requests
BeautifulSoup
Beautiful Soup is an open-source Python library for parsing XML and HTML files. It parses the HTML and XML document in a tree-like structure which data can further be extracted very easily. Before using the beautiful soup make sure that you have installed it for your Python environment. It can easily be installed using pip command.
pip install beautifulsoup4
Access Internet Data with Python Example Let's extract the data of covid cases in India, from the official website of the worldometer, and access total number of Coronavirus Cases, Death and Recoveries.

When we start scraping data from a webpage, there are two things we need from the page itself, first the URL and second the HTML tag which data we supposed to extract.
Note: For accessing data from a webpage using scraping, you should also have some knowledge of HTML. You should know what is a tag in HTML what is class, id, and other attributes .
You can find the URL from the search bar, but which tag data you should be scraping that can be found out by inspecting the page. To inspect the page right-click on the web page and click on the Inspect button, you will see a similar image.
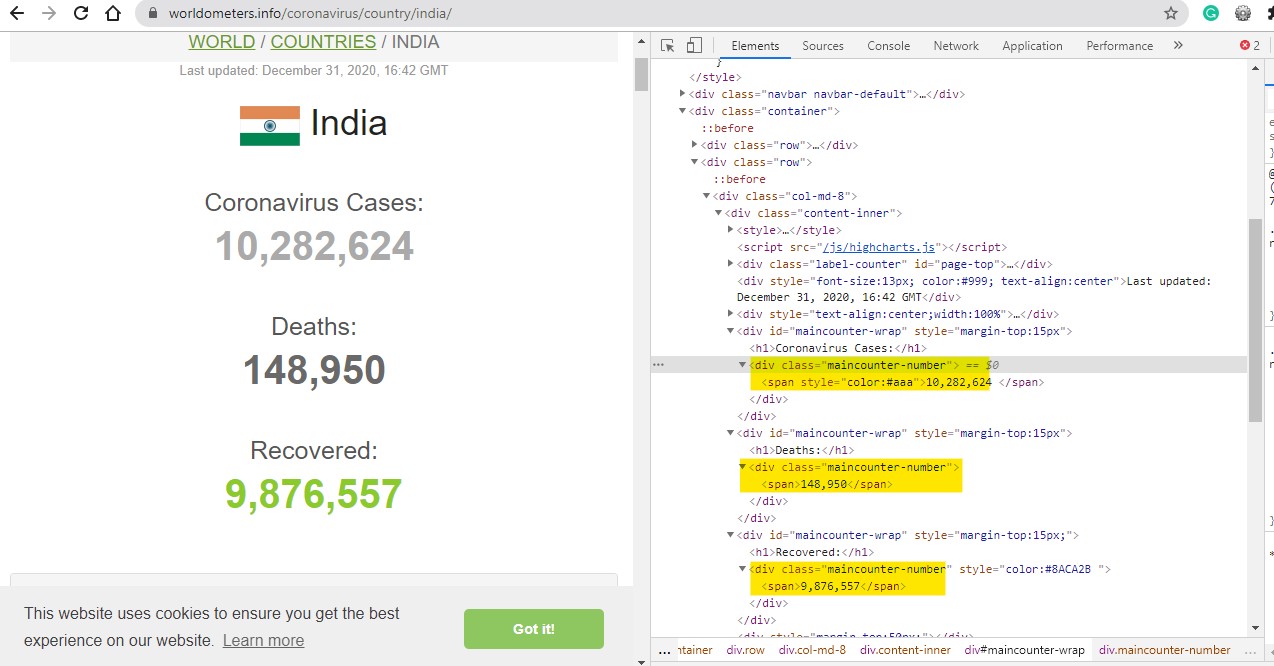
As you can see that the data for the
Coronavirus Cases, Deaths
and
Recovered
are inside the <div> tags with similar class name
maincounter-number
. Now let's access these three data using Python requests and beautiful soup library.
#Python program
import requests
from bs4 import BeautifulSoup
url="https://www.worldometers.info/coronavirus/country/india/"
#send request to url
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
#access all div tags with calss name maincounter-number
data = soup.find_all("div","maincounter-number")
TotalCases , Deaths, Recovered = list(data)
print("TotalCases:" ,TotalCases.text.strip())
print("Deaths:", Deaths.text.strip())
print("Recovered:", Recovered.text.strip())
Output
TotalCases: 10,282,624
Deaths: 148,950
Recovered:9,876,557
Summary
- While Loop in Python
- Python For Loop
- Type Conversion and Type Casting in Python
- Python Variables, Constants and Literals
- Keywords and Identifiers in Python
- Best Python IDEs and Code Editors
- Python vs JavaScript
- Port Vulnerability Scanner in Python
- Python List append and extend method
- Detect Shapes in Python



Leave a Comment on this Post