

Machine learning (ML) focuses on providing machines with the ability to learn without being programmed and improve their decision-making capability over each iteration through experience. Here, we will discuss the best machine learning frameworks. ML is the subset of artificial intelligence, and it has several real-world applications.
In other words, machine learning enables machines to learn just like humans. For example, natural language processing (NLP), pattern recognition, image classification, clustering, and regression are all different applications of machine learning. Also, ML is extensively used for performing data science, and it helps businesses perform predictive data analysis, make business decisions, and forecast the future.
In this article, we will be discussing the best machine learning frameworks that machine learning engineers and data scientists use to develop robust machine learning models. But before moving to that, let's quickly overview the types of algorithms that machine learning uses.
Types of Machine Learning Algorithms
Machine learning can be performed through a set of algorithms. These algorithms are of three types:
1. Supervised Machine Learning
Supervised machine learning trains a machine by providing a set of data and the expected outcome, i.e., we already labeled the data. The machine builds a model based on the training data set. Once the model is built, another data set (testing data set) is fed to the machine to check the accuracy of the model.
Examples of supervised machine learning algorithms are classification algorithms, like Support Vector Machines, decision trees, linear classifiers, and regression algorithms, like linear regression and polynomial regression.
2. Unsupervised Machine Learning
This type of algorithm provides no training to a machine. Hence, the machine finds similarities and patterns in the data all by itself (without any form of supervision). Also, unsupervised learning is more complex than supervised learning.
Some examples of unsupervised machine learning algorithms are clustering algorithms, like K-means clustering, DBScan, dimensionality reduction, and Association rules, like Apriori and ECLAT.
3. Reinforcement Machine Learning
The third type of machine learning is reinforcement learning. It is also the most complex of the trio. It involves an agent that has to take actions in a specific environment to ensure maximum rewards. The reward is cumulative and follows certain rules.
Game theory, information theory, multi-agent systems, and statistics use reinforcement learning. Reinforcement machine learning is also referred to as neuro-dynamic or approximate dynamic programming. Markov Decision Process and Q learning are vital learning models in reinforcement learning.
Relationship Between Artificial Intelligence, Machine Learning, and Deep Learning
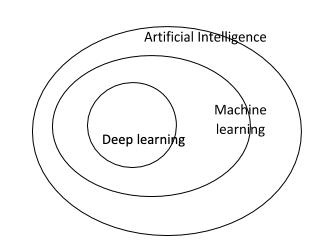
Machine learning is a subset of artificial intelligence, and deep learning is a subset of machine learning. Thus, we can say that both machine learning and deep learning are subsets of artificial intelligence. You can understand the relation between the three from the below image:
 Also, you can check out our
AI vs ML vs Deep Learning
article that highlights all the key differences between the three in detail.
Also, you can check out our
AI vs ML vs Deep Learning
article that highlights all the key differences between the three in detail.
Top 12 Machine Learning Frameworks
There are many machine learning frameworks out there. Thus, it will become difficult for you to find one that best suits your needs, especially if you're new to it. Therefore, to make the selection process easier for you, we have listed the best machine learning frameworks along with their brief overviews as follows:
1. TensorFlow

We'll start our list of the best machine learning frameworks with TensorFlow, which is an open-source machine learning and deep learning framework developed by Google. Its libraries use graphs to describe workflows and complex networks in a simple manner.
TensorFlow finds use in both research projects and real-world applications. The key highlight of TensorFlow is its ability to create neural networks. Also, TensorFlow works on all major operating systems, including Windows, macOS, and Linux. TensorFlow is built using the C++ programming language, and it supports various programming languages, including Python , Java, and C. The machine learning framework is ideal to use for image recognition, image search, language translation, and speech recognition.
2. Keras

Keras is a deep learning framework that has broad community support. It is written in Python and supports many neural-network computation engines, especially Convolutional Neural Networks. Keras is used along with low-level computation libraries like TensorFlow as a high-level API. Also, it comes with an interface that is easier to use as compared to TensorFlow.
The other ‘Backend’ engines/libraries that support Keras are Theano and CNTK. Developers can create new modules as a set of classes and functions using Python in Keras. The existing stand-alone modules can be used to create new models.
With Keras, code deployment is fast, and it supports many devices, including Raspberry Pi. Moreover, you can use Keras with single or multiple GPUs at the same time. The base of Keras is the ‘Model,’ which defines the whole network graph. You can use the same model or add more layers to it to suit your requirements. You can build a simple sequential model with the following steps:
- Creating a sequential model
- Convolution layer
- MaxPooling layer
- Dense layer
- Dropout layer
- Network compilation, training, and evaluation
The popular applications of Keras are face recognition, computer vision, and other use cases that require deep neural networks.
3. Scikit-learn
Perhaps the most widely used and useful general-purpose machine learning framework, Scikit-learn, contains all the tools for statistics, including classification, regression, dimensionality reduction, and clustering. It is free and contains almost all the popular algorithms, like Naïve Bayes, Decision tree, KNN, and SVM.
Scikit-learn is written in Python, C, and C++ and built on top of the SciPy ML library. Some of the key features of Scikit-learn are:
- Free, open-source, and commercially usable (BSD license).
- Along with ML algorithms, it also has pre-processing, cross-validation, and visualization algorithms.
- Excellent documentation and community support.
Scikit-learn is more like a high-level API for building standard machine learning models. Unlike TensorFlow, it doesn’t come with an automatic differentiation toolkit. Also, Scikit-learn is apt for building quick algorithms, whereas TensorFlow requires more training time, thus making it more suitable for deep learning networks.
4. H2O.ai
The next name that we pick for our list of the best machine learning libraries is H2O.ai, which is not a true machine learning framework. Instead, it is an open-source platform that aims to make ML easier for business users. Business users need not worry about deployment, performance tuning, and other low-level tasks with H20.ai, and they can gain insights from data quickly. H2O.ai is a suite of products with the most popular ones mentioned below:
- H2O – It is an open-source, distributed, and in-memory platform for ML and predictive analysis. It can build production-ready models for supervised and unsupervised algorithms, like classification and clustering. H2O has a simple yet effective UI known as flow.
- Steam – This is an enterprise offering where data scientists can build, train and deploy ML models that users can access by various applications via APIs.
- Driverless AI – Though named so, it is not specific to autonomous driving but also performs automatic feature engineering, model selection, tuning and ensembles, and helps in calibrating parameters that optimize the algorithms for specific use-cases.
H2O.ai also provides a REST API for external programs to access its capabilities over HTTP via JSON. The machine learning platform also supports algorithms other than supervised and unsupervised algorithms, like quantile, early stopping, and Word2Vec.
5. Microsoft Cognitive Toolkit
Abbreviated as CNTK, Microsoft Cognitive Toolkit is an open-source kit for commercial-level distributed deep learning. It is fast, scalable, and reliable. Microsoft products like Skype, Cortana, and Bing use CNTK to develop commercial-grade systems using sophisticated algorithms. It offers built-in components like CNN, RNN, FFN, reinforcement learning, supervised and unsupervised learning, LSTM, generative adversarial networks, and many more.
Furthermore, developers can add their custom components using Python on the GPU. Microsoft Cognitive Toolkit offers automatic hyperparameter tuning. Also, the GPU Memory can fit large models and still maintain speed, efficiency, and parallel processing.
The ML toolkit offers both high-level and low-level APIs to suit different business needs. You can evaluate the models using C++, C#, BrainScript, and Python. You can also train and host the models on the Azure cloud and even perform real-time training.
6. MXNet
MXNet is a dynamic and flexible library for deep learning. It is short for mix and maximizes. It supports many programming languages, including Python, R, C++, Java, JavaScript, Julia, Perl, and MATLAB. The ML library is portable and scalable to multiple GPUs and machines.
Both MS Azure and AWS cloud providers support MXNet. Due to its ability to distribute processing into multiple GPUs, MXNet offers high speed and performance. MXNet supports many tools and libraries to build applications in the field of computer vision, natural language processing, time series, and more.
Also, it supports automatic differentiation, i.e., it automatically calculates the gradients required for training a model. The ML library has a hybrid frontend, i.e., the Gluon Python API, that lets developers switch to a symbolic mode for higher performance and faster execution.
7. Apple’s Core ML
Core ML comes as one of the most important ML frameworks for iOS and other operating systems used by Apple devices, like macOS, watchOS, and tvOS. It can produce real-time results with low latency. This is especially useful for the real-time prediction of live videos (successive frames) or images on a device. The application can run in offline mode (without network or API calls) without any loss of data.
Some of the popular applications of Core ML are real-time image recognition, face detection, text prediction, and speaker identification. The machine learning models are pre-trained on the cloud and then changed to Core ML format, which can be directly added to the required Xcode project. Some frameworks that support Core ML are Vision, GamePlaykit, and NLP.
8. Caffe
Caffe is an expressive deep learning framework made for speed and modularity. It was earlier available under the BSD 2-Clause license; however, Facebook open-sourced it in 2017. Interestingly, Caffe was integrated with Apache Spark to produce a distributed deep learning framework, namely CaffeOnSpark.
Written in C++, it has Python and MATLAB programming interfaces. Caffe is much suitable for industrial deployments, like vision and speech, as well as research projects. It can process more than 60 million images in a day on a single GPU, which is quite fast.
The machine learning framework is suitable for major deep learning networks like CNNs, long short-term memory, long-term recurrent convolutional networks, and fully connected neural networks. It stores data in the form of blobs. Also, the properties of the blob define how the information gets stored across various neural network layers. Caffe is most suitable for mobile devices and computationally constrained platforms.
9. Amazon Machine learning
Amazon ML is a comprehensive service that uses a set of products consisting of algorithms and mathematical models for developing predictive applications. The service reads data through Redshift, RDS, and Amazon S3 and uses the Amazon ML API and AWS management console to visualize the data. Also, it allows you to use the S3 buckets to import and export data to other AWS services.
You can use Amazon Machine Learning for various algorithms that perform classification, dimensionality reduction, regression, and reinforcement learning (through Amazon SageMaker RL). Also, the ML framework is suitable for those working with other AWS services and just starting with ML due to the limited choice of algorithms.
The main algorithm (model) for which AWS ML was built is the Stochastic Gradient Descent (SGD) model. AWS ML is becoming popular because it is easy to learn and implement, and it also saves a lot of development time. AWS-optimized TensorFlow framework can achieve near-linear scalability and better utilization of GPU by improving the way tasks are distributed across GPUs.
10. Theano
Built on top of the NumPy library, Theano is an open-source project written in Python and CUDA. It contains a compiler for manipulating and evaluating mathematical expressions, particularly matrix-based expressions (n-dimensional arrays). Following are the key features of Theano:
- It can handle complex computations required for large neural network algorithms.
- Theano supports both convolutional and recurrent neural networks.
- It is extremely fast, even for data-intensive computations (about 140 times faster than CPU) through the use of GPU.
- The ml library allows dynamic code generation for faster evaluation of expressions like differentiation, matrix arithmetic, and gradient computation.
- It comes with tools for unit testing, debugging , and verifying bugs and potential issues.
- The ML framework offers tight integration with NumPy.
- Theano is also capable of performing differentiation (computing derivatives) efficiently.
- It provides stable output expressions for large datasets.
Theano builds an entire computation graph for the model and compiles the same into a highly efficient code by applying optimization techniques. A special operation, known as ‘function,’ then pushes the compiled code into the Theano runtime. The ‘function’ is iteratively executed to train the neural network. One can visualize a computation graph using the printing package in the Theano library.
11. Shogun
The number eleven spot on our list of the best machine learning frameworks goes to Shogun. It is open-source software written in C++. Shogun offers a wide range of algorithms and data structures for different machine learning problems.
This framework also provides interfaces for Python, R, Java, Ruby, MATLAB, C#, and Octave. The primary purpose of developing Shogun was mainly for kernel-based algorithms, like Support Vector Machines, that we can use for both classification and regression. It provides a generic interface to 15 SVM implementations, like SVMLin, SVMlight, GPDT, LibSVM, and LibLinear.
Also, you can combine SVMs with over 35 different kernel functions. Apart from kernel functions, Shogun also supports dimensionality reduction algorithms (like PCA, multidimensional scaling, diffusion maps, and Laplacian Eigenmaps), online learning algorithms, clustering algorithms (like k-Means and GMM), hidden Markov models, linear discriminant analysis, perception, and many more.
Shogun provides an implementation for many kernels like gaussian, polynomial, sigmoid, or linear kernels for numerical data, and weighted degree, spectrum, and weighted degree with shifts for a special type of data. An example of special data could be the DNA sequence.
12. Torch
Torch is a popular scientific computing framework that uses GPUs for computing. It uses LuaJIT scripting language with C/CUDA underlying implementation. Torch makes scientific computing easy and offers high flexibility. It has vast community support, and there are many dedicated packages for image networking, parallel processing, computer vision, signal processing, audio, video networking, and so on.
Moreover, Torch provides a lot of routines for slicing, indexing, resizing, transposing, and other data processing methods. Torch is open-source, and 'torch' is the name of the core package. It supports all major mathematical operations, like the dot product, matrix-vector product, matrix-matrix multiplication, and statistical distributions, such as normal, uniform, and multinomial.
The nn package in Torch is used for neural networks. It supports both feedforward and backpropagation operations using the respective methods. PyTorch is a Python implementation of the Torch framework, which provides dynamic graphs, fast computation, and a host of libraries for machine learning tasks. Facebook extensively uses Torch for its AI development. IBM, Twitter, Idiap, Google, Nvidia, and Yandex also use Torch for research purposes.
How to Pick the Best Among these Machine Learning Frameworks?
While picking a machine learning framework, you need to figure out your business (or personal) use case. As we have seen above, each ML framework has its unique strengths and can serve different purposes. For example, for building quick algorithms and models, you can use a general-purpose ML framework like Scikit-learn. On the other hand, for more complex calculations and data-intensive operations, Theano and TensorFlow are the most suitable machine learning frameworks. If you have less time to build a deep learning network, you can use Azure ML studio.
Conclusion
In this article, we have learned about the most important and widely used machine learning frameworks. These frameworks can significantly simplify your code so you can focus more on business logic.
Among the frameworks listed above, TensorFlow, Caffe, and CNTK are brilliant frameworks for deep learning, while frameworks like Scikit-learn and MOA are great for generic machine learning. Also, you can use Google Cloud ML, Amazon ML, and Azure ML Studio if you want to create ML models on the cloud.
Nonetheless, it's quite important that you keep all your personal preferences and project requirements in mind so that you can choose the best machine learning framework. If you have any suggestions or queries, feel free to share them with us in the comments section below.
People are also reading:
- What is Machine Learning?
- Best Machine Learning Interview Questions
- How to become a Machine Learning Engineer?
- Machine Learning Projects
- Classification in Machine Learning
- AI vs. ML vs. Deep Learning
- Machine Learning Applications
- Machine Learning Algorithm
- Data Science vs. Machine Learning
- Decision Tree in Machine Learning



Leave a Comment on this Post