

The article lists the 10 best big data frameworks to process data efficiently. However, please note that this is not a universal list, i.e., your views might differ from ours. Therefore, we would love to know about your best picks in the comments section at the end of the article. Thanks in advance!
Big data has been the buzzword in this data-driven world. It refers to massive datasets that keep growing each day. For example, the number of Facebook users keeps growing daily, and users' data also grows as they browse through Facebook.
Today, companies rely entirely on data to make actionable insights and deliver value to their customers that satisfy them. However, the data generated is structured as well as unstructured. Also, it can be disordered and too complex.
Data must be in a usable format to make the most out of it. As a result, there is a need to transform big data into a structured and usable format. However, doing it consumes plenty of time and requires a lot of technical expertise if done manually.
Fortunately, big data frameworks can help get this task done faster. They help gain insights from heaps of complex datasets on time. This, in turn, facilitates the decision-making process.
Through this article, I will make you aware of some best big data frameworks available on the market with their features. But, let me first introduce you briefly to the big data framework definition and its advantages.
What is a Big Data Framework?
It is a computer program or tool to possess and analyze massive amounts of data quickly and efficiently while maintaining security. It helps derive valuable insights from enormous amounts of data in an instant.
Advantages
- Provide a structure and standard reference to organizations to explore the full potential of big data.
- Improve the approach to collecting, storing, managing, and sharing data, and use data effectively for business purposes.
- Perform advanced analytics to get better insights and make intelligent data-driven decisions.
- Tap data from various sources and capture different types of data to find the best - and most useful - insights.
- Faster and affordable. It can reuse standard pieces of code and has excellent community support.
- Facilitate advanced analytics through visualization and predictive analysis .
Besides processing and analyzing data, these frameworks have other applications, as follows:
- Business intelligence (BI) and analytics
- Artificial intelligence and machine learning
- Streaming data processing
Today, companies are seeking professionals that have the potential to derive valuable insights from complex and gigantic datasets. Hence, learning and gaining hands-on experience with at least one big data framework can help you land a lucrative job. So, without wasting any time, let us hop on our list.
10 Best Big Data Frameworks To Process Data
The market of big data frameworks started with Apache Hadoop, which revolutionized the storage and processing of massive heaps of data.
So, let us start our list with Apache Hadoop!
1. Apache Hadoop
GitHub Stars: 13.2K
|
Pros |
Cons |
|
|
The most popular big data framework, Hadoop, is open-source, Java-based. It provides batch processing and data storage services. It has a humungous architecture consisting of many layers, like HDFS and YARN, for data processing.
In Hadoop, storage happens across various hardware machines arranged as clusters. Furthermore, it provides a distributed environment with the following main components:
- HDFS (Hadoop Distributed File System): HDFS is the hardware layer. It stores data in the Hadoop cluster, including replication and storage activities across all the data clusters.
- YARN (Yet Another Resource Negotiator): YARN is responsible for job scheduling and resource management.
- MapReduce: The software layer works as the batch processing engine. Also, it processes vast amounts of data in a cluster.
Hadoop is fast and can store petabytes of data. The performance gets better as the data storage space increases. Many big companies like Alibaba, Amazon, eBay, and Facebook use HDFS to store data and integrate with many popular big data analytics frameworks.
2. Apache Spark
GitHub Stars: 34.9K

|
Pros |
Cons |
|
|
Spark is a batch-processing framework with enhanced data streaming processing capabilities. It is the most popular framework for data processing right now. It facilitates in-memory computations, making the same superfast. It integrates with Hadoop seamlessly and can act as a standalone cluster tool.
Many famous companies, like Amazon, Hitachi solutions, Baidu, and Nokia, use Spark. Moreover, it supports four languages: Python, R, Java, and Scala.
It has five main components:
- HDFS and HBase form the first layer of storage systems.
- YARN manages the resources.
- It has a core engine that performs task and memory management and defines RDD (Resilient Distributed Datasets) API. This API is responsible for distributing data across the nodes for parallel processing.
- It has utilities containing Spark SQL to execute SQL queries for stream processing, GraphX to process graph data, and MLLib for machine learning algorithms .
- API for integration with programming languages like Java and Python.
3. MapReduce
|
Pros |
Cons |
|
|
MapReduce is a big data search engine and part of the Hadoop framework. Initially, it was just an algorithm to process vast volumes of data parallelly. But now, it is more than that. It works in 3 stages:
- Map: This stage handles the pre-processing and filtration of data.
- Shuffle: Shuffles (sorts) the data as per the output key generated by the map function.
- Reduce: Reduces the data based on the function set by the user and produces the final output.
Although many new technologies have come, MapReduce is popular and most used because it is resilient, stable, fast, scalable, and follows a simple model. Further, it is secure and fault-tolerant for failures like crashes and omissions.
4. Apache Hive
GitHub Stars: 4.6K

|
Pros |
Cons |
|
Facebook designed Apache Hive on the top of HDFS as an ETL and data warehousing tool. It consists of 3 components: clients, services and storage, and computing.
Moreover, Apache Hive has its own declarative language for querying, HiveQL, which is highly suitable for data-intensive jobs.
The Hive engine converts queries and requests into MapReduce task chains using the following components:
- Parser : Takes in the SQL request and parses and sorts them.
- Optimizer: Optimizes the sorted requests.
- Executor: Sends the optimized tasks to the MapReduce framework.
Companies like JP Morgan, Facebook, Accenture, and PayPal use Hive.
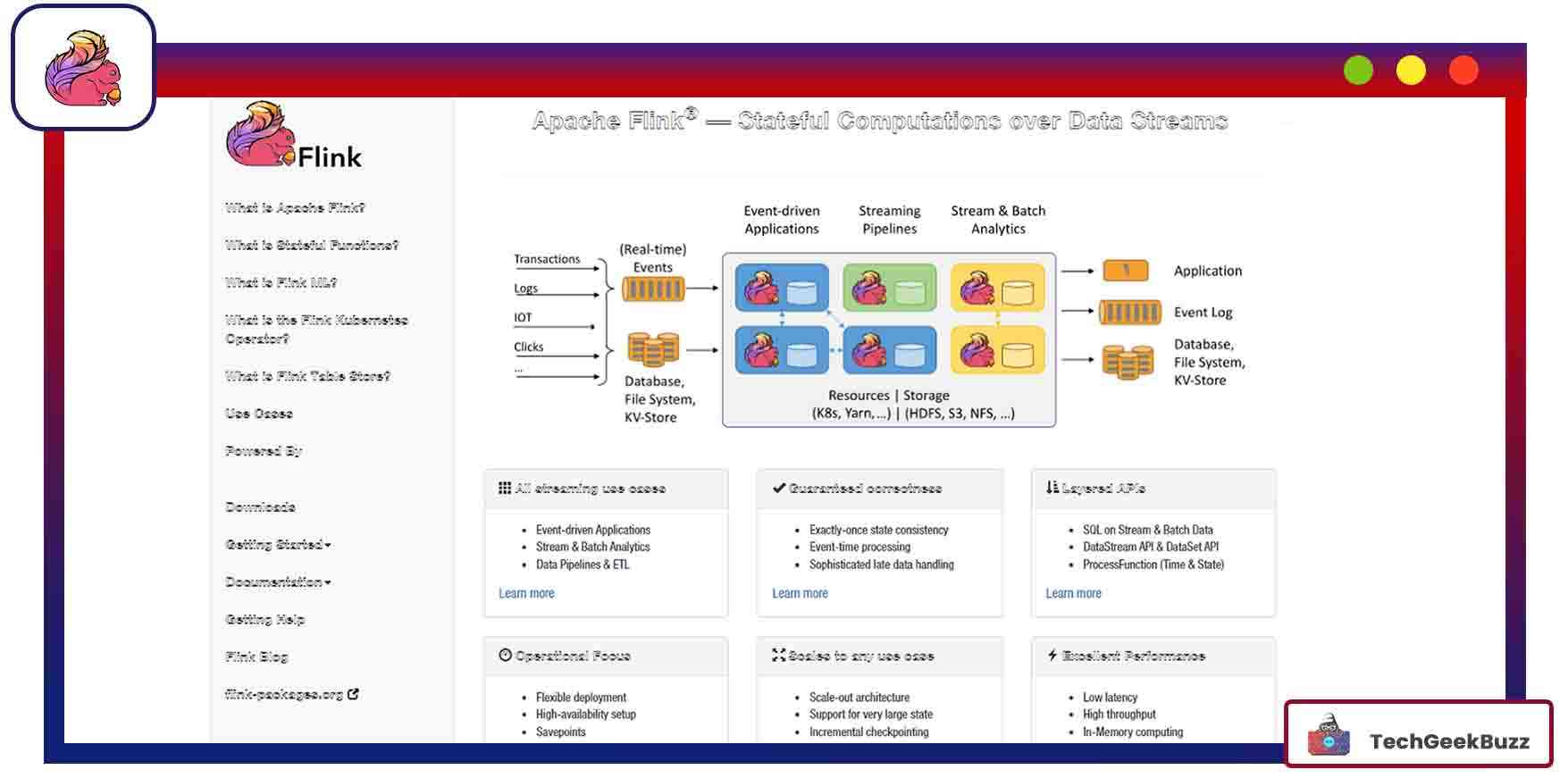
5. Flink
GitHub Stars: 20.6K
|
Pros |
Cons |
|
|
Flink is an open-source single-stream processing engine based on the Kappa architecture. It has one processor that treats the input as a stream. The streaming engine processes the data in real time. Batch processing is a particular case of streaming.
The framework’s architecture has the following components:
- Client: Takes the program, builds a job dataflow graph, and passes it to the job manager. The client is also responsible for retrieving job results.
- Job Manager: Creates the execution graph based on the dataflow graph received from the client. Then, it assigns and supervises the jobs to task managers in the cluster.
- Task Manager: Executes tasks assigned by the JobManager. Multiple task managers perform their specified tasks parallelly.
- Program: It is the code that is run on the Flink cluster.
Flink APIs are available for Java, Python, and Scala. It also provides utility methods for typical operations, event processing, machine learning, and graph processing.
Furthermore, it processes data in the blink of an eye. It is highly scalable and scales thousands of nodes of a cluster.
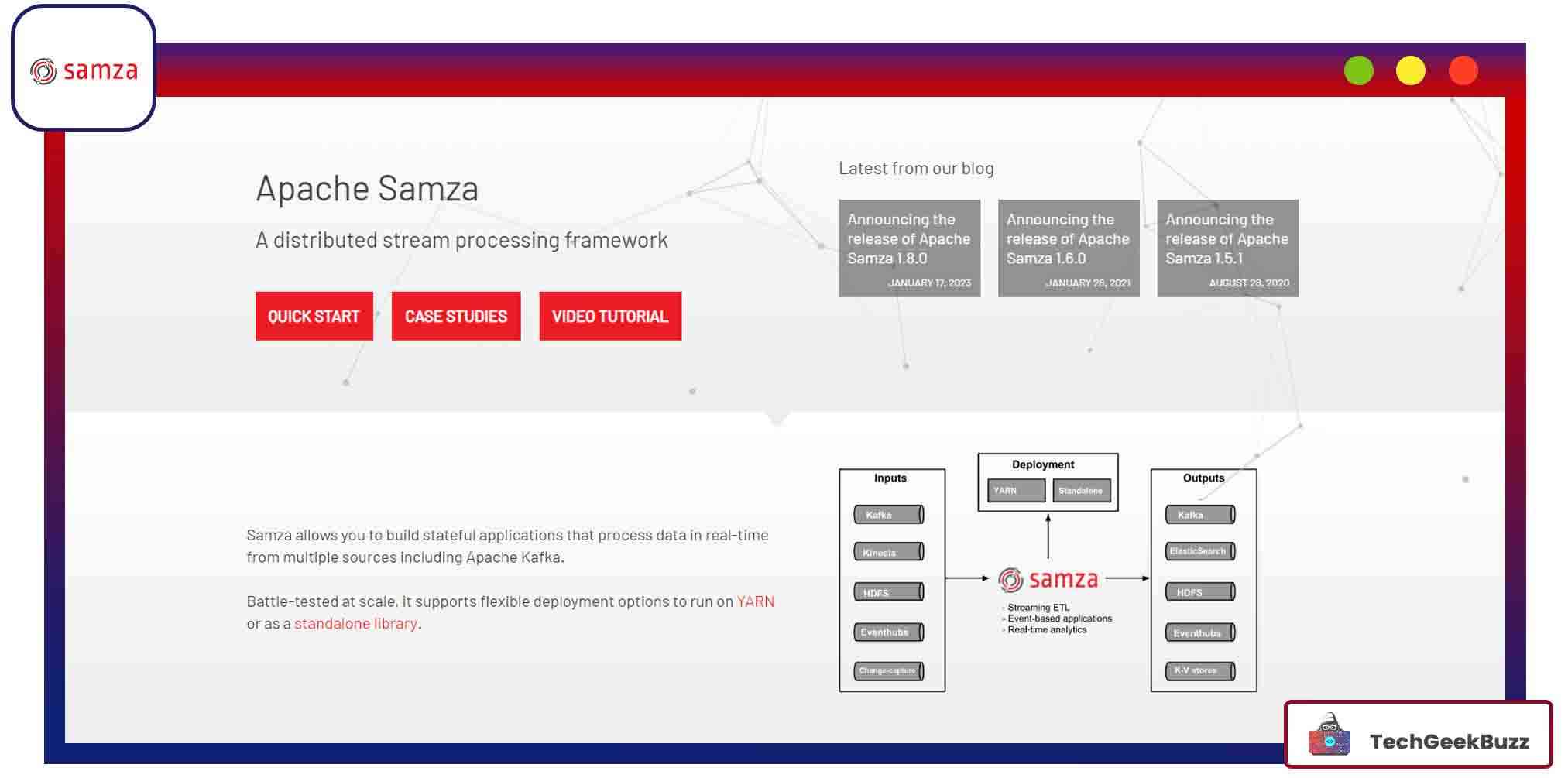
6. Samza
|
Pros |
Cons |
|
|
The primary aim of designing Samza was to solve the problem of batch processing latency (considerable turn-around time) problem. Consequently, it supports the development of stateful applications that can process real-time data from various sources. Some of the most common input sources for Samza are Kafka, HDFS, Kinesis, and Eventhubs.
Samza’s unique feature is that it is horizontally scalable. You can process batch and streaming data using the same code (write once, run anywhere!). It also has rich APIs, like Streams DSL, Samza SQL, or Apache Beam APIs.
LinkedIn created the Samza architecture, which consists of the following components:
- Streaming layer: Provides partitioned streams that are durable and can be replicated.
- Execution layer: Schedules and coordinates tasks across machines.
- Processing layer: Processes and applies transformations to the input stream.
The streaming layer (Kafka, Hadoop, and so on) and the execution layer (YARN and Mesos) are pluggable components.
7. Storm
GitHub Stars: 6.4K
|
Pros |
Cons |
|
|
Storm works with a substantial real-time data flow. The sole purpose of developing this framework was to handle low latency. It is highly scalable, and it can recover faster after downtime.
It was Twitter’s first big data framework, after which giants like Yahoo, Yelp, and Alibaba adopted it. Storm supports Java, Python, Ruby, and Fancy .
The Storm architecture follows the master-slave concept and consists of 2 nodes:
- Master node: Allocates tasks and monitors machine/cluster failures.
- Worker node: Also called supervisor nodes, worker nodes are responsible for task completion.
Storm is platform-independent and fault-tolerant. It has an advanced Trident topology that maintains the state. Although it is said to be stateless, it stores its state using Apache ZooKeeper.
8. Impala
GitHub Stars: 920
|
Pros |
Cons |
|
|
Impala is an open-source parallel processing query engine that processes enormous volumes of data in a single Hadoop cluster. It supports C++ and Java. Just like Hive has its own query language, Impala has one too! It has low latency and high performance and gives a near RDBMS experience in terms of performance and usability.
The framework is like the best of both worlds: the performance and support of SQL-like query language and Hadoop's flexibility and scalability. It is based on daemon processes that monitor query execution, making it faster than Hive.
Moreover, Impala supports in-memory data processing. It is decoupled from its storage engine and has three components:
- Impala daemon (impalad): It runs on all the nodes with Impala installed. Upon receiving a query, impalad reads and writes it to data files and distributes the queries to the nodes in that cluster. The results are then received by the coordinating node that initially took the query.
- statestore: Checks the health of each Impala daemon and updates other daemons about the same.
- metastore & metadata: Metastore is a centralized database where table and column definitions and information are stored. Impala nodes cache metadata locally so that it can be retrieved faster.
9. Presto
GitHub Stars: 14.4K
|
Pros |
Cons |
|
|
Presto is an open-source distributed SQL tool suitable for smaller datasets (Tb). It provides fast analytics and supports non-relational sources like HDFS, Cassandra, and MongoDB. It also supports relational database sources like MSSQL, Redshift, and MySQL.
The framework has a memory-based architecture where query execution runs in parallel and provides results in seconds.
Presto runs on Hadoop and uses a similar architecture to that of Massively Parallel Processing. It has the following nodes:
- Coordinator nodes : Users submit their queries to this node. Later, it uses a custom query and the engine to distribute and schedule queries across the worker nodes.
- Worker nodes: Executes the assigned queries parallelly and, thus, saves time.
Facebook, Airbnb, Netflix, Nasdaq, and many more giant firms use Presto as their query engine.
10. HBase
GitHub Stars: 4.8K
|
Pros |
Cons |
|
|
HBase can store humongous amounts of data and process and access it randomly. Built on top of the Hadoop file system, HBase is linearly scalable and uses distributed column-oriented database architecture. It also provides data replication across clusters and automatic fail-over support.
The framework also has a Java API for clients. Tables are split into regions, where a dedicated server manages each region. Furthermore, regions are vertically split into stores, which are saved as files in the Hadoop file system.
There are three main components in HBase:
- MasterServer: Maintains the state of the cluster, handles load balancing, and is responsible for creating tables and columns.
- RegionServer: Handles data-related operations, determines the size of each region, and handles read and write requests for all the regions under it.
- Client library: Provides methods for the client to communicate.
Conclusion
That completes our list of the 10 best big data frameworks. Each of them has unique features and purposes. There is no such one-size-fits-all framework because every project has different requirements.
For example, if your project needs batch processing, Spark is a great choice. For data-intensive jobs, Hive is much more suitable. It is easier to learn too. Storm and Flink are both excellent choices for dealing with real-time streaming requirements.
If you know any other popular big data framework, let us know in the comments section.
People are also reading:


