

A data warehouse (DW), also known as a computing data warehouse, is a type of data management system that supports various business intelligence activities, particularly analytics. It acts as a central repository for data collected from heterogeneous sources. It stores all historical data in one place, and this data is used for generating analytical reports that help enterprises and businesses make better decisions. Like a database , a data warehouse also has a schema that defines how the data is arranged and the relationships between the data.
In this article, we will discuss one of the most common types of data warehouse schema, called Star schema. Prior to it, we will give a brief overview of the data warehouse schema. Also, in the later parts of this article, we will highlight the key advantages and disadvantages of Star schema along with one example to help you understand the Star schema better.
So, without further ado, let’s get started!
What is a Data Warehouse Schema?
A data warehouse schema is a skeletal structure that logically describes the content of a data warehouse. In a data warehouse, we use schema to define how database entities, like fact tables and dimension tables, organize data and represent their logical relationships.
Databases use relational models for their logical structure, whereas data warehouses use Star schema, Snowflake schema, and Fact Constellation schema. Each data warehouse schema consists of fact tables and dimension tables. A fact table consists of keys to dimension tables. On the other hand, a dimension table consists of keys to a fact table and their corresponding attributes.
- Star Schema: A star schema consists of only one fact table and multiple dimension tables. A fact table is present at the center surrounded by multiple dimension tables, forming a star-like shape. Hence, the name star schema.
- Snowflake Schema: Like a Star schema, a Snowflake schema also consists of one fact table and multiple dimension tables. The significant difference between the Star and Snowflake schema is that the tables in the Snowflake schema are normalized. A fact table in the Snowflake schema is surrounded by multiple hierarchies of dimension tables, and the structure resembles a snowflake.
- Fact Constellation Schema: Also referred to as the Galaxy schema. It consists of multiple fact tables and multiple dimension tables, and two fact tables can share the same dimension table in the Fact Constellation schema. The entire structure looks like a collection of stars, hence the name Galaxy schema.
What is Star Schema?
A Star schema is the most fundamental type of data warehouse schema, and it is extensively used to develop data warehouses and dimensional data marts. A data mart is the subset of a data warehouse focused on a single or specific line of business. Star schema consists of one fact table holding measurable, quantitative data and multiple dimension tables that store descriptive attributes of the data present in the fact table. This type of data warehouse schema is ideal for handling simple queries. Now, let us discuss fact tables and dimension tables in detail.
Fact Tables
A fact table consists of two columns, where one column contains numeric values, and the other has foreign keys to all the associated dimension tables. The primary key in a fact table is a composite key comprising the foreign keys to all dimension tables. We can define fact tables as:
- Transactional fact tables that record facts about a particular event.
- Snapshot fact tables that record facts at a specific point in time.
- Accumulating snapshot tables that record aggregate facts at a specific point in time.
Dimension Tables
Dimension tables store descriptive information of the data stored in fact tables. They are smaller in size than fact tables and contain descriptive or textual values. Some common examples of dimension tables are:
- Range dimension tables: They specify the ranges of measurable quantities, like dollar or time values.
- Product dimension tables: They describe products.
- Geography dimension tables: They specify location data, like country, city, or state.
- Employee dimension tables: They contain employee data.
Advantages of Star Schema
The following are the advantages of Star schema:
- Simpler Queries: Star schema’s join logic is more straightforward than the join logic needed to fetch data from other highly-normalized transactional schemas.
- Simplified Business Reporting Logic: The Star schema makes the business reporting logic more simplified than other high-normalized transactional schemas.
- Query Performance Gains: The read-only reporting applications perform better in Star schema than other normalized transactional schemas.
- Feeding Cubes: We can efficiently design OLAP cubes since all OLAP systems use the Star schema.
Disadvantages of Star Schema
Some significant downsides of the Star schema are:
- Data Integrity: As all the tables in the Star scheme are in the denormalized state, there is a lack of data integrity.
- Lack of Flexibility: The Star schema is not flexible when it comes to the analytical needs as a normalized data model. It is more purpose-built towards the viewing of data and does not support complex analytics.
- Lack of Entity Relationships: Star schemas do not easily support many-to-many relationships between business entities.
Example of Star Schema
Let us consider the Sales database classified by date, store, and product. The below diagram represents the Star schema of Sales.
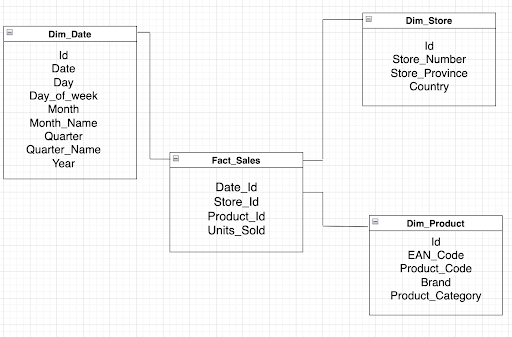
In the above diagram, Fact_Sales is the fact table that references three dimension tables, namely Dim_Product, Dim_Store, and Dim_Date. The Fact_Sales table consists of one primary key that combines three other primary keys, namely, Date_Id, Store_Id, and Product_Id, and one non-primary key, i.e., Units_Sold.
The Unit_Sold column is a measure or metric used for analysis or calculation. Every dimension table has one primary key column, called ‘Id’, and all other columns are non-primary. The non-primary columns of Dim_Date are Date, Day, Day_of_week, Month, Month_Name, Quarter, Quarter_name, Year. Dim_Store has non-primary columns as Store_Number, Store_Province, and Country. Dim_Product has non-primary columns as EAN_Code, Product_Code, Brand, and Product_Category
Conclusion
The star schema is the most typical modeling paradigm in the data warehouse consisting of only one fact table and multiple dimension tables. It has a simple design and is a perfect data warehouse schema for dealing with simpler queries. Hopefully, this article helped you in developing a better understanding of the Star schema. Also, if you have any thoughts on this article, feel free to share them with us in the comments section below.
People are also reading:


