

What is data mining? Have you wondered why enterprises want to collect so much data? What is done with that data upon acquiring it? Does all of the acquired data make sense? What comes out of that data? We will answer all these questions and many more in this article. When we acquire massive datasets from different sources, the result is often very messy. So much so that it is almost impossible to make any sense of it.
To make the data usable, we have to prepare it before applying any analytics to it. Data mining refers to the entire process of data acquisition, preparation, sorting, visualization, transformation, filtering, and manipulation to make it usable and understandable for getting insights. In essence, data mining is obtaining knowledge from data or Knowledge Discovery in Databases, i.e., KDD.
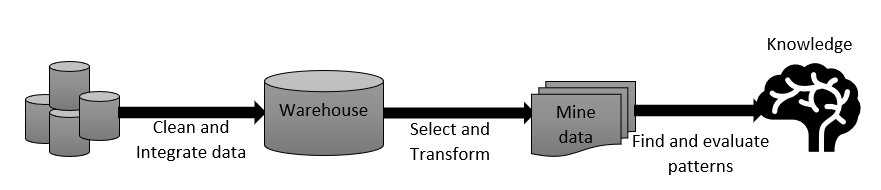
Data mining involves statistics, computing, machine learning, visualization, and analysis, as we will see later. Data snooping, fishing and dredging are different methods of mining data.
For example, web scraping is a common method of data mining. Some important data types gathered during the mining process are game data, medical and personal data, digital media, text reports, memos, surveillance videos and images, business transactions, scientific data, and engineering data.
Data Mining Architecture
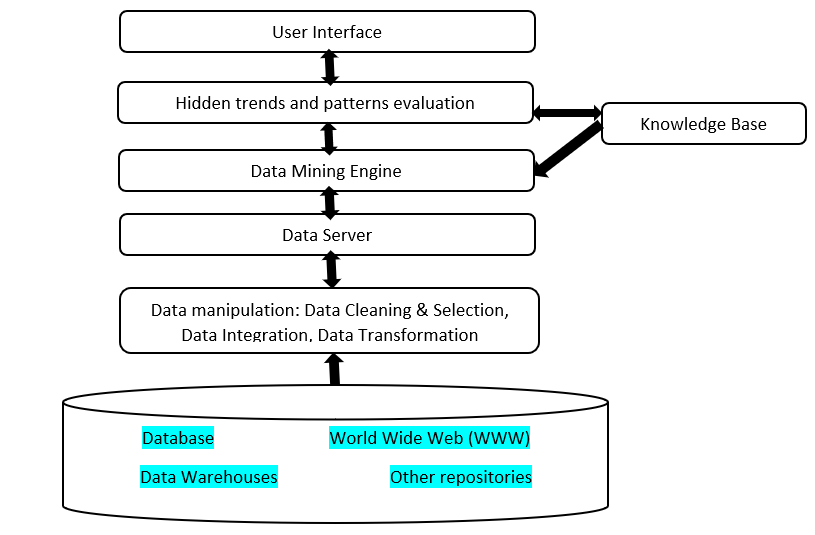
As you can see in the above diagram, the architecture is quite simple. We will explain the same in the following section (we will see from bottom to top):
- Starts with collecting data from various sources, like databases, data warehouses, the web, and other repositories.
- This data is raw and unstructured, and hence cleaned, i.e., missing, redundant, duplicate data, etc., is removed, and data is integrated into one structure.
- The integrated data goes into a single data warehousing server.
- Next, the data is fed to the data mining engine that applies various tools and techniques to find patterns and insights.
- The knowledge base consists of data from past experiences, user behaviors, and beliefs and is beneficial for finding patterns. Once a model is created, it interacts with the knowledge base to improve reliability and accuracy.
Types of Data That Can be Mined
It is possible to mine both simple and complex forms of data. Data mining tools are well-equipped to handle any data type. Some examples are:
- Spatial Databases : These store information about geographical locations in the form of lines, latitude, longitude, shapes, etc. Examples are maps and GPS.
- Multimedia Databases : Databases that store information in videos, audio, images, and text formats. For example, YouTube and an e-books database.
- Time Series Databases : Time Series data is listed or indexed in the order of time. It is taken at equally or unequally spaced intervals of time. For example, weather data, stock exchange, and health monitoring (ECG). Measurements spaced at equal intervals are called Metrics, and those spaced at irregular time intervals are called Events.
- Flat Files : These are in text or binary form and are easiest to read by data mining algorithms. These are available in various formats, like .csv and .txt.
- Relational Databases : Relational databases organize data in the form of tables that have multiple rows and columns. SQL is a common relational database .
- Transactional Databases : Transactional databases have timestamps attached to each data value, for example, ATMs, distributed systems, and banking systems.
- Data Warehouse : It is constructing data from various data sources and involves data cleaning, integration, and consolidation.
- World Wide Web (WWW) : The web can contain any form of data, may it be video, audio, or text. Data can be differentiated using individual URLs via browsers.
Types of Attributes for Data Mining
An attribute is simply a field that stores data. Attributes refer to different features of an object. For example, height, weight, and skin color are all attributes of a person. These attributes can be put into a vector, known as the attribute vector, for data pre-processing. Attributes can be of different types:
-
Qualitative Attributes:
- Nominal : Attributes that are in alphabetical form. For example, the status of the leave application: New, Pending approval, Approved. Similarly, the color of the eyes: Black, Brown, Green, etc.
- Ordinal : These have a meaningful logical order. For example, income tax slabs, grades in exams, etc.
- Binary : Only two possible values, 0/1, Yes/No, True/False. There are two types, symmetric , where both the values are equally important, and asymmetric , where one of the values is more important than the other. For example, for a cricket match to happen, it is more important than the ‘willItRain’ attribute is false.
-
Quantitative Attributes:
- Discrete : Such data attributes have finite values. They can be in a categorical or numerical form. For example, colors of fruits, types of food, age, etc.
- Continuous : Attributes that can have any number of values (up to infinity). For example, height, weight, etc.
Data Mining Tools and Techniques
Various ready-to-use and user-friendly tools are available that are much more suitable even for those with no or little technical knowledge, i.e., business analysts, stakeholders, etc., who want to work on data to get quick insights. These tools work towards a common goal, which is finding patterns and hidden trends in data that were never seen before. Some standard tools (most are also free and open-source) are:
1. WEKA
WEKA provides a lot of mechanisms to cleanse raw data before applying any machine learning algorithms. The cleaned data has to be further pre-processed (or transformed). For pre-processing, you need various algorithms (these are different from ml algorithms), like classification, regression, clustering, or association. WEKA provides the implementation of many such algorithms that helps in attribute selection and hence, gives a reduced dataset. It also offers statistical output and visualization tools to help detect patterns.
2. R
R contains rich libraries and tools to perform data exploration and analysis. It provides algorithms for various techniques, like decision trees, text mining, time-series analysis, social network analysis, parallel computing, and outlier detection. R is easy to learn and use. Learn more about Data mining using R.
3. Rapid Miner
This tool provides an integrated platform for data processing, data preparation, text mining, machine learning, deep learning, and predictive analytics. It is intuitive and has a friendly UI with useful features. RapidMiner is not free but comes with a trial period. Also, RapidMiner Turbo Prep makes data preparation extremely easy and less time-consuming, as you can instantly see the results of the changes you make through the UI.
4. Knime
Short for Konstanz Information Miner, Knime is a free and open-source mining tool. It has a modular data pipelining concept (Lego of Analytics) and allows for an assembly of nodes for data pre-processing, modeling, analysis, and visualization through its GUI. You can drag and drop workflow items, perform complex statistics, transform data through its ETL tools, and apply machine learning.
You can start creating workflows, filter data using column filter nodes, remove redundant, null, unknown, and missing values using row filter nodes, visualize data using different plots and generate the output as a report with just a few clicks.
5. SAS
For those with no or limited statistical knowledge, SAS predictive modeler can be a good choice. You can perform data mining tasks by creating compelling visualizations. Model comparisons, reporting, and management can be quickly done, and you can achieve a very sophisticated level of data preparation and exploration, much more suitable for enterprise applications with massive datasets.
SAS UI offers batch processing and is easy to use. Excel, Spark, SQL, and Python are some other useful
tools for data mining
, which are equally popular too. Popular techniques that data mining experts use are (explanations of each are out of scope for this article):
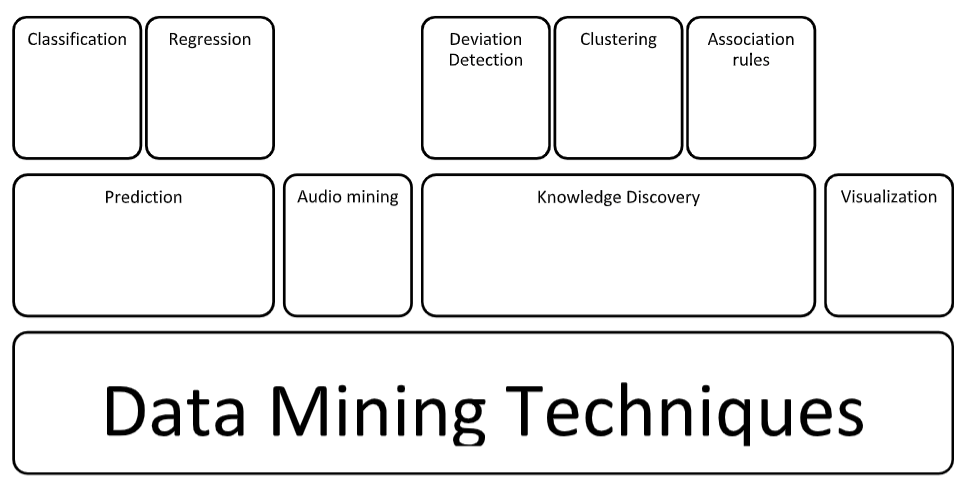
1. Statistical, machine learning, and probability methods
Includes many popular methods, like regression, variance analysis, generalized linear models, factor analysis, discriminant analysis, and data compression using clustering , decision trees , association rules, sequential patterns, classification rules , and joint probability distribution.
2. Visual methods
Uses computer graphics, plots, charts, high-performance computing, pattern recognition, multimedia systems, etc., for visual representation and performs data analysis on a vast scale. You need to know how to infer the patterns visually.
3. Audio mining
A unique alternative to visual methods that uses audio signals to detect data patterns or features from data mining results. An example can be the mining of a music database to find the genre or patterns in the audio based on rhythm, tone, pitch, melody, etc.
Data Mining Applications
Data mining finds its applications in various industries, like telecom, credit card, insurance, medical and pharma, retail and marketing, recommender systems, engineering and science, and intrusion detection and prevention. Some typical applications are:
- Prediction of customer credit policy analysis, credit rating, detection of money laundering, unusual or suspicious access, and targeted marketing.
- Identify customer behavior and purchase patterns, achieve better customer retention, and improve services.
- Analyze the effectiveness of sales campaigns and generate product recommendations.
- Monitoring network intrusions, social media analysis, and monitoring software bugs.
- Analysis of streaming data to prevent fraud.
Data Mining Job Roles and Salary
The key responsibilities of a data mining specialist are:
- Store and maintain data in multi-dimensional databases.
- Find trends and patterns and summarize the data.
- Use statistical techniques and programming to create predictive models.
- Create data visualizations to mine, analyze and report data.
- Generate actionable insights and find new ways to enhance the overall productivity of the industry.
You need a lot of technical skills, some business and communication skills, and good analytical skills. Familiarity with data analysis tools (at least one of the tools mentioned above), knowledge of languages like Python, R, Perl, or Java, and working knowledge of operating systems are a must.
The salary package typically offered to a data mining specialist, as per payscale.com, is around $62,225 per year. You can take up roles like data mining analyst, web analytics manager, and director of analytics. At the highest level (director of analytics), you will be paid about 94k-115k USD approximately.
Pros and Cons of Data Mining
Advantages
- Understanding customer behavior and habits and serving personalized content based on the same.
- Trend analysis.
- Easy marketing campaigns.
Disadvantages
- Invasion of privacy.
- A lot of irrelevant and incomplete information may result in inaccurate results.
Data Science vs Data Mining
We often compare data science and data mining. The difference between the two, however, is very simple. Data science is a bigger term that encompasses data mining, which is just one step in the entire data science lifecycle where you deal with the technicalities of data. As such, the job roles of a data mining analyst and a data scientist are different. Learn more about the differences between the two in our detailed blog on Data science vs. Data Mining .
Conclusion
We have seen how to extract knowledge from huge datasets using different techniques and tools to get useful insights and patterns from data. We call this data mining. Some people find it analogous to Knowledge Discovery, while others feel that data mining is an essential step in the knowledge discovery process. Data mining involves pre-processing, integrating, transforming, analyzing, and visualizing data to get patterns and insights. Data can further be modeled to generate models and evaluate the performance.
People are also reading:



Leave a Comment on this Post