

Generally, we use a web browser to download files from the internet. The downloading of a file is similar to accessing a web page hosted on a server. We sent the get request to the file url address and in response, we get the file. In this Python tutorial, I will walk you through a Python program to download files from the internet using a simple HTTP request. Also, I will be downloading the Python 3.9 .exe file from the internet using the Python program. But before we discuss the Python code to download files, let's take a look at the libraries that we need to use to make the Python program workable.
Required Python Libraries
1. Python
requests
library
requests
is one of the most
popular Python libraries
that is used to send HTTP requests. Most
Python web frameworks
use this library for HTTP requests. In this tutorial, we will be using this library to send GET requests to the file url that we want to download.
requests
is not a part of Python Standard libraries, so we need to install it for our Python environment using the following pip command:
pip install requests
2. Python
progress
library (optional)
The second library that we will be using is
progress
,
which is an open-source third-party Python library. We will use this library to display a console-based progress bar for visualizing the downloading progress of the file. To download the progress library for your Python environment, we will run the following pip command on the terminal or command prompt:
pip install progress
How to Download Files in Python?
Alright, now let's get started with the Python program to download a file from the internet. Let's start with importing the modules.
import requests
from progress.bar import Bar
After importing the modules, let's define the
file_url
string variable that represents the url for the file that we want to download. In this tutorial, I will download the Python 3.9.exe file from the official website of Python, and for that, I need the url path of the file. To get the URL of the file, we can simply right-click on the download button and copy the link address.
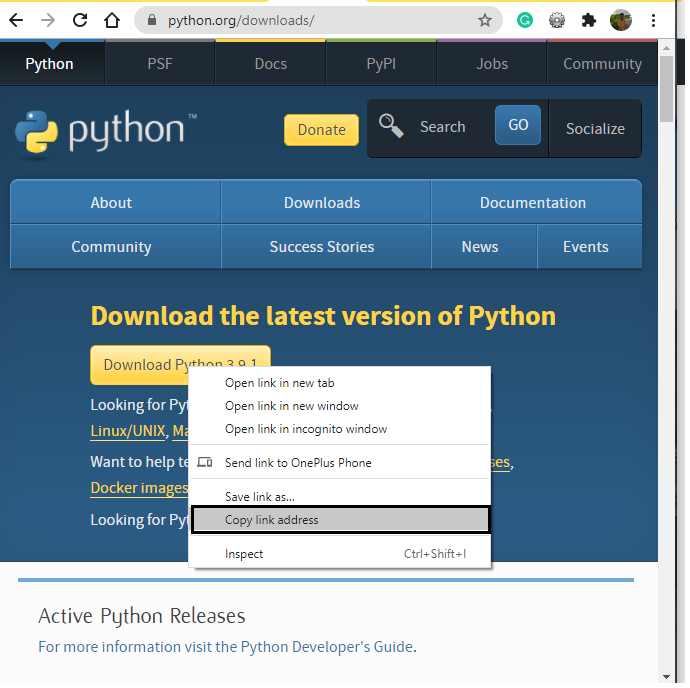
file_url="https://www.python.org/ftp/python/3.9.1/python-3.9.1-amd64.exe"
filename = file_url.split("/")[-1]
#send get request
response = requests.get(file_url, stream=True)
The requests.get(file_url, stream=True) function will send a get request to the
file_url
, and the
stream=True
attribute will make sure that the response does not download the file at once, instead it downloads the file in the data chunks.
After sending the get request to the file url, you will receive the file response in chunks that you can iterate over and download the complete file. Before we start downloading the file data in our local system let's get the total size of the response file:
file_size = int(response.headers.get("Content-Length", 0))
headers.get("Content-Length")
will return the total length of data which represents the total size of data in bytes.
Now, let's get every chunk of data from the
response
object using
iter_content()
function:
with Bar(f'Downloading {filename}', fill='*',suffix='%(percent)d%%') as bar:
#write file in binary mode
with open(filename,"wb") as file:
#iterate over the response in data chunks
for data in response.iter_content(chunk_size=file_size//100):
file.write(data)
bar.next() #increase downloading bar
print("File has been downloaded successfully")
Bar(f'Downloading {filename}', fill='*',suffix='%(percent)d%%') as bar
statement is for the downloading bar progress.
with open(filename,"wb") as file:
statement will create a filename and write data in binary mode.
for data in response.iter_content(chunk_size=file_size//100):
is a statement that will iterate over the response, and get the specified number of data chunks in every iteration. With each iteration, we will get
file_size//100
data values. Now put all the code together and execute.
Complete Python Program to Download Files from the Internet
from progress.bar import Bar
import requests #pip install requests
file_url="https://www.python.org/ftp/python/3.9.1/python-3.9.1-amd64.exe"
filename = file_url.split("/")[-1]
#send get request
response = requests.get(file_url, stream=True)
file_size = int(response.headers.get("Content-Length", 0))
with Bar(f'Downloading {filename}', fill='*',suffix='%(percent)d%%') as bar:
#write file in binary mode
with open(filename,"wb") as file:
#iterate over the response in data chunks
for data in response.iter_content(chunk_size=file_size//100):
file.write(data)
bar.next() #increase downloading bar
print("File has been downloaded successfully")
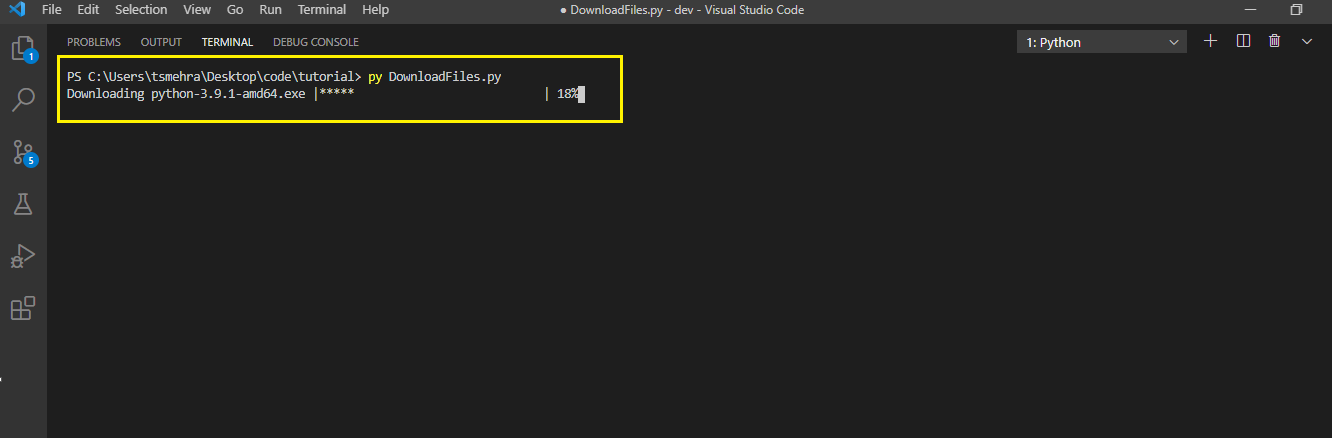
Output
When you execute the above code, the downloading process will begin. After the process gets finished, you can check your directory, and there you will see the downloaded file.
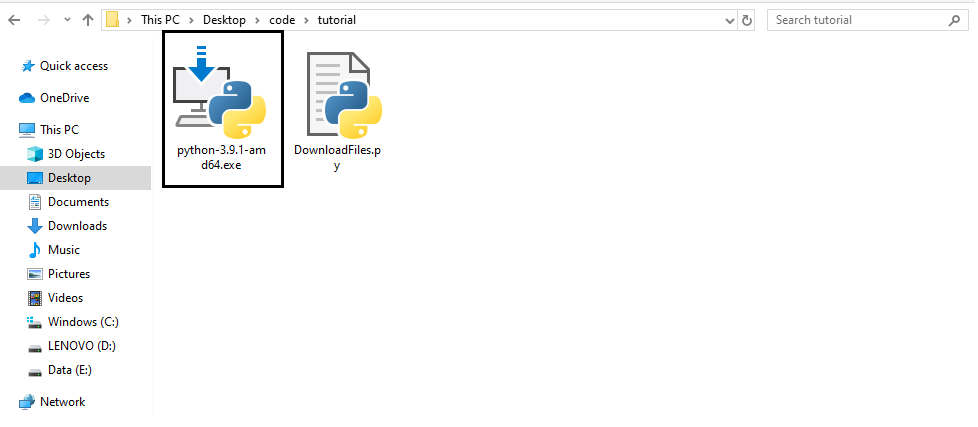
Conclusion
In this Python tutorial, you learned "How to download files from the internet using Python". In the above program, I have used two third-party libraries
requests
and
progress
. By using the requests library, I sent a GET request to the file url. Also, with the progress library, I displayed the downloading progress bar, which is nothing but just the 100 write data lines with 100 iterations. If you want to learn how to download all the images from a web page using Python, you can
click here
.
People are also reading:



Leave a Comment on this Post